Documentation
Running LLMs Locally
User Interface
Advanced
Command Line Interface - lms
API
REST Endpoints
LM Studio SDK (TypeScript)
Idle TTL and Auto-Evict
Idle TTL and Auto-Evict
LM Studio 0.3.9 introduced the ability to set a time-to-live (TTL) for API models, and optionally auto-evict previously loaded models before loading new ones.
These features complement LM Studio's on-demand model loading (JIT) to automate efficient memory management and reduce the need for manual intervention.
Background
-
JIT loadingmakes it easy to use your LM Studio models in other apps: you don't need to manually load the model first before being able to use it. However, this also means that models can stay loaded in memory even when they're not being used.[Default: enabled] -
(New)
Idle TTL(technically: Time-To-Live) defines how long a model can stay loaded in memory without receiving any requests. When the TTL expires, the model is automatically unloaded from memory. You can set a TTL using thettlfield in your request payload.[Default: 60 minutes] -
(New)
Auto-Evictis a feature that unloads previously JIT loaded models before loading new ones. This enables easy switching between models from client apps without having to manually unload them first. You can enable or disable this feature in Developer tab > Server Settings.[Default: enabled]
Idle TTL
Use case: imagine you're using an app like Zed, Cline, or Continue.dev to interact with LLMs served by LM Studio. These apps leverage JIT to load models on-demand the first time you use them.
Problem: When you're not actively using a model, you might don't want it to remain loaded in memory.
Solution: Set a TTL for models loaded via API requests. The idle timer resets every time the model receives a request, so it won't disappear while you use it. A model is considered idle if it's not doing any work. When the idle TTL expires, the model is automatically unloaded from memory.
Set App-default Idle TTL
By default, JIT-loaded models have a TTL of 60 minutes. You can configure a default TTL value for any model loaded via JIT like so:
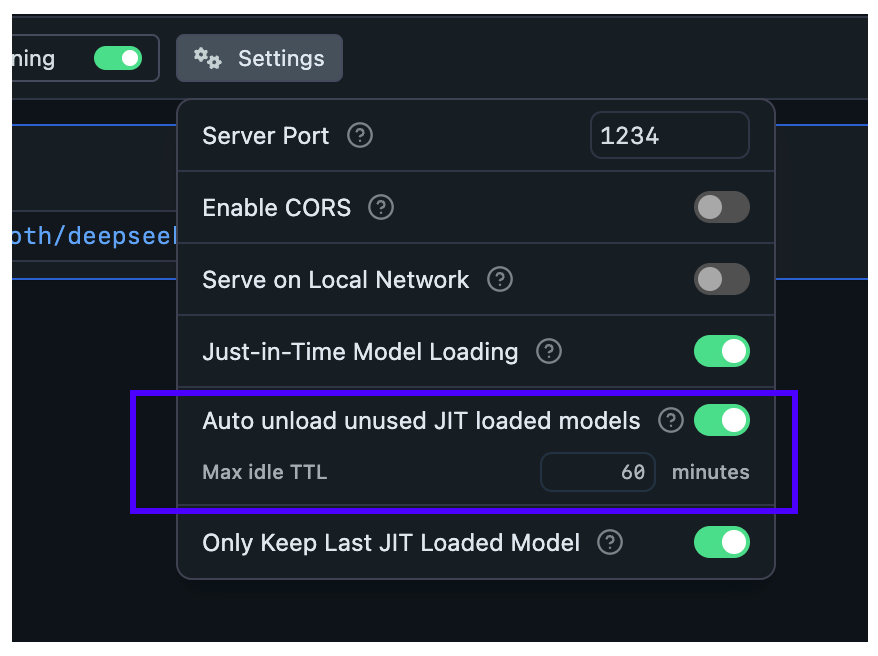
Set a default TTL value. Will be used for all JIT loaded models unless specified otherwise in the request payload
Set per-model TTL-model in API requests
When JIT loading is enabled, the first request to a model will load it into memory. You can specify a TTL for that model in the request payload.
This works for requests targeting both the OpenAI compatibility API and the LM Studio's REST API:
curl http://localhost:1234/api/v0/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "deepseek-r1-distill-qwen-7b", + "ttl": 300, "messages": [ ... ] }'
This will set a TTL of 5 minutes (300 seconds) for this model if it is JIT loaded.
Set TTL for models loaded with lms
By default, models loaded with lms load do not have a TTL, and will remain loaded in memory until you manually unload them.
You can set a TTL for a model loaded with lms like so:
lms load <model> --ttl 3600
Load a <model> with a TTL of 1 hour (3600 seconds)
Specify TTL when loading models in the server tab
You can also set a TTL when loading a model in the server tab like so
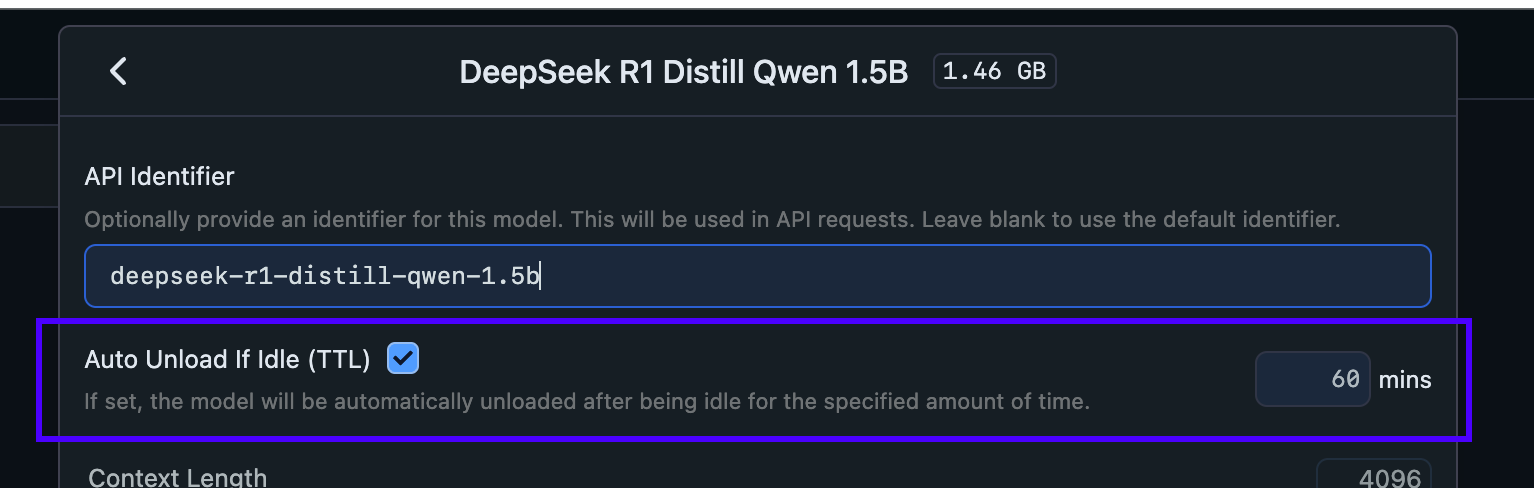
Set a TTL value when loading a model in the server tab
Configure Auto-Evict for JIT loaded models
With this setting, you can ensure new models loaded via JIT automatically unload previously loaded models first.
This is useful when you want to switch between models from another app without worrying about memory building up with unused models.
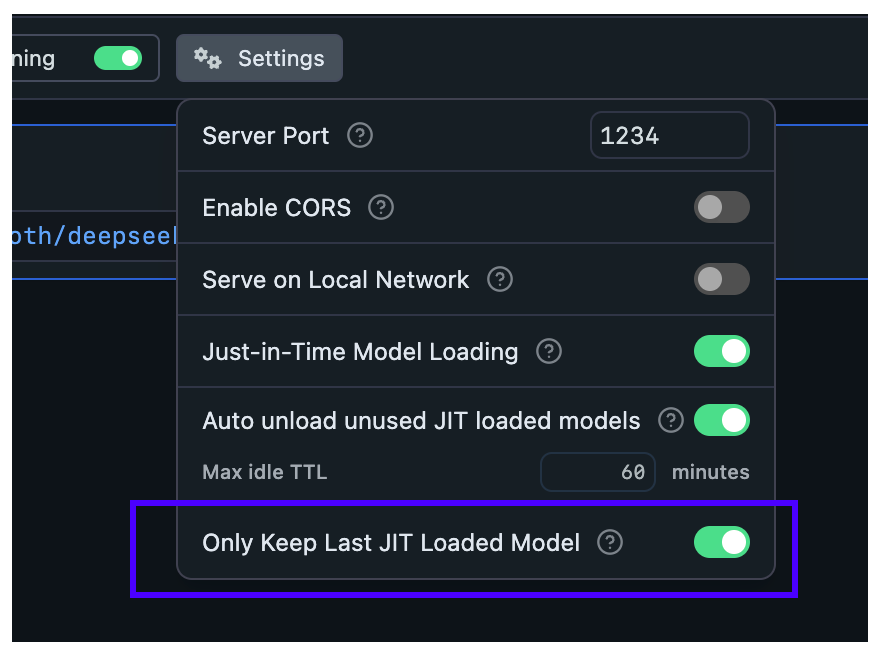
Enable or disable Auto-Evict for JIT loaded models in the Developer tab > Server Settings
When Auto-Evict is ON (default):
- At most
1model is kept loaded in memory at a time (when loaded via JIT) - Non-JIT loaded models are not affected
When Auto-Evict is OFF:
- Switching models from an external app will keep previous models loaded in memory
- Models will remain loaded until either:
- Their TTL expires
- You manually unload them
This feature works in tandem with TTL to provide better memory management for your workflow.
Nomenclature
TTL: Time-To-Live, is a term borrowed from networking protocols and cache systems. It defines how long a resource can remain allocated before it's considered stale and evicted.