Documentation
Running LLMs Locally
User Interface
Advanced
Command Line Interface - lms
API
Get started with LM Studio
Get started with LM Studio
You can use openly available Large Language Models (LLMs) like Llama 3.1, Phi-3, and Gemma 2 locally in LM Studio, leveraging your computer's CPU and optionally the GPU.
Double check computer meets the minimum system requirements.
You might sometimes see terms such as open-source models or open-weights models. Different models might be released under different licenses and varying degrees of 'openness'. In order to run a model locally, you need to be able to get access to its "weights", often distributed as one or more files that end with .gguf, .safetensors etc.
Getting up and running
First, install the latest version of LM Studio. You can get it from here.
Once you're all set up, you need to download your first LLM.
1. Download an LLM to your computer
Head over to the Discover tab to download models. Pick one of the curated options or search for models by search query (e.g. "Llama"). See more in-depth information about downloading models here.
The Discover tab in LM Studio
2. Load a model to memory
Head over to the Chat tab, and
- Open the model loader
- Select one of the models you downloaded (or sideloaded).
- Optionally, choose load configuration parameters.

Quickly open the model loader with cmd + L on macOS or ctrl + L on Windows/Linux
What does loading a model mean?
Loading a model typically means allocating memory to be able to accomodate the model's weights and other parameters in your computer's RAM.
3. Chat!
Once the model is loaded, you can start a back-and-forth conversation with the model in the Chat tab.
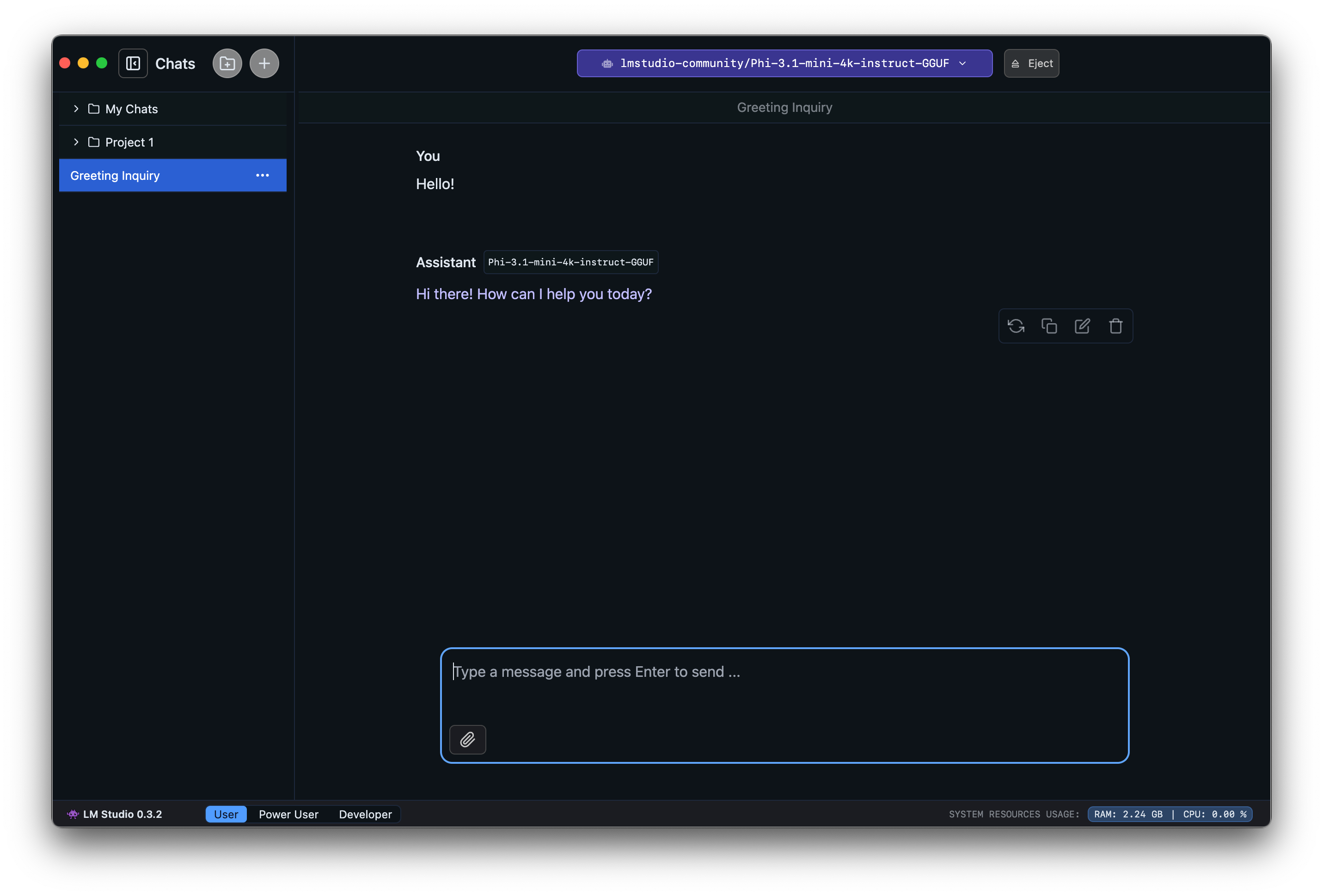
LM Studio on macOS
Community
Chat with other LM Studio users, discuss LLMs, hardware, and more on the LM Studio Discord server.